This is part of a series, start here!
This is Uncle Bob’s attempt at synthesize previous architectural patterns and concepts.
Based on a common thread between Ports & Adapters, Onion, EBI, he wrote an article as ‘an attempt at integrating all these architectures into a single actionable idea’.1
High level
The original article starts with a diagram similar to this:
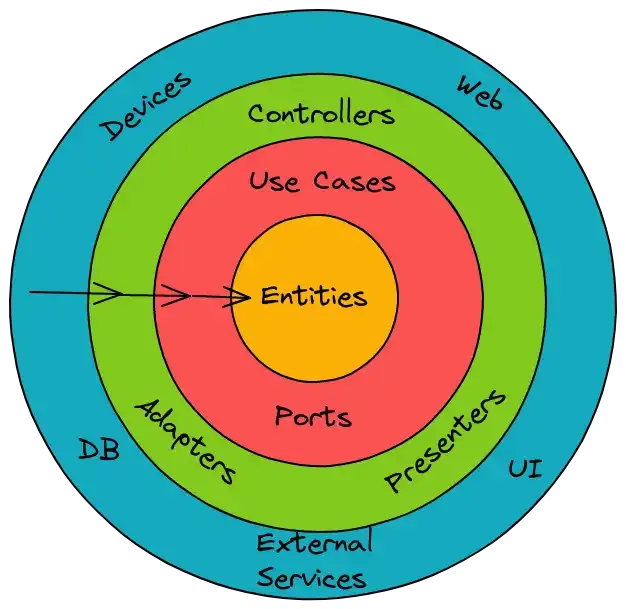
Project structure
At face value, the diagram seems to suggest a project structure as such:
Entities├── Tenant├── Landlord├── RentRepositories├── TenantRepo├── LandlordRepo├── RentRepoUseCases├── PayRent├── RequestRent├── RequestRepair├── CalculateRent...There are however a couple of shortcomings here:
- Low cohesion: Modify one Use Case, and you’ll have to change code in three different modules
- No clear purpose: A newcomer would have to dig through the directory structure to know what the application is for
Borrowing some key concepts like Bounded Context from DDD, the previous system can be represented as such:
Tenant├── Tenant├── TenantRepo├── PayRent├── RequestRepairLandlord├── Landlord├── LandlordRepo├── RequestRentRent├── Rent├── RentRepo├── CalculateRent...Low level
There’s a pretty useful diagram in the slides Bob uses in his conferences.
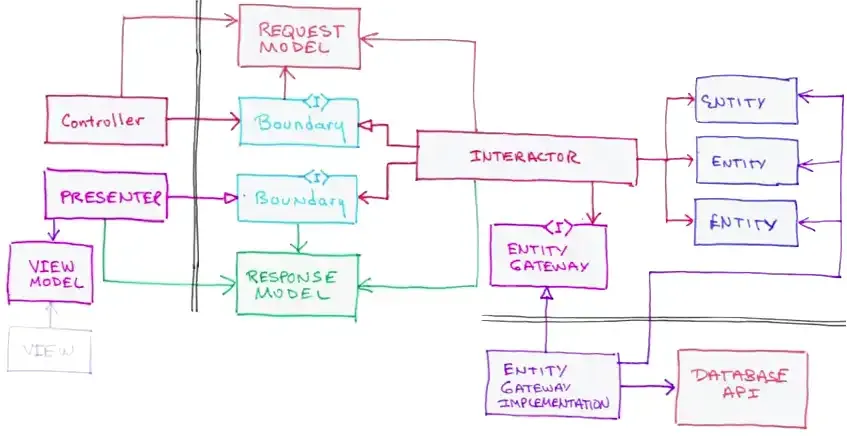
Cool, but a bit overwhelming. Let’s start with Entity and Interactor2 and build the diagram with concepts from other notable architectures.3
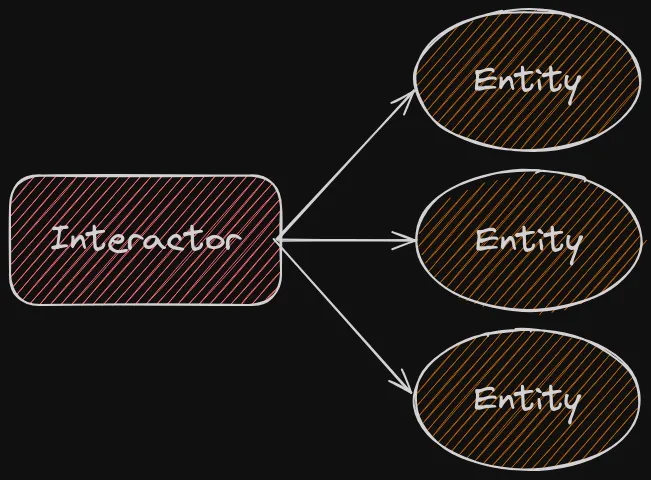
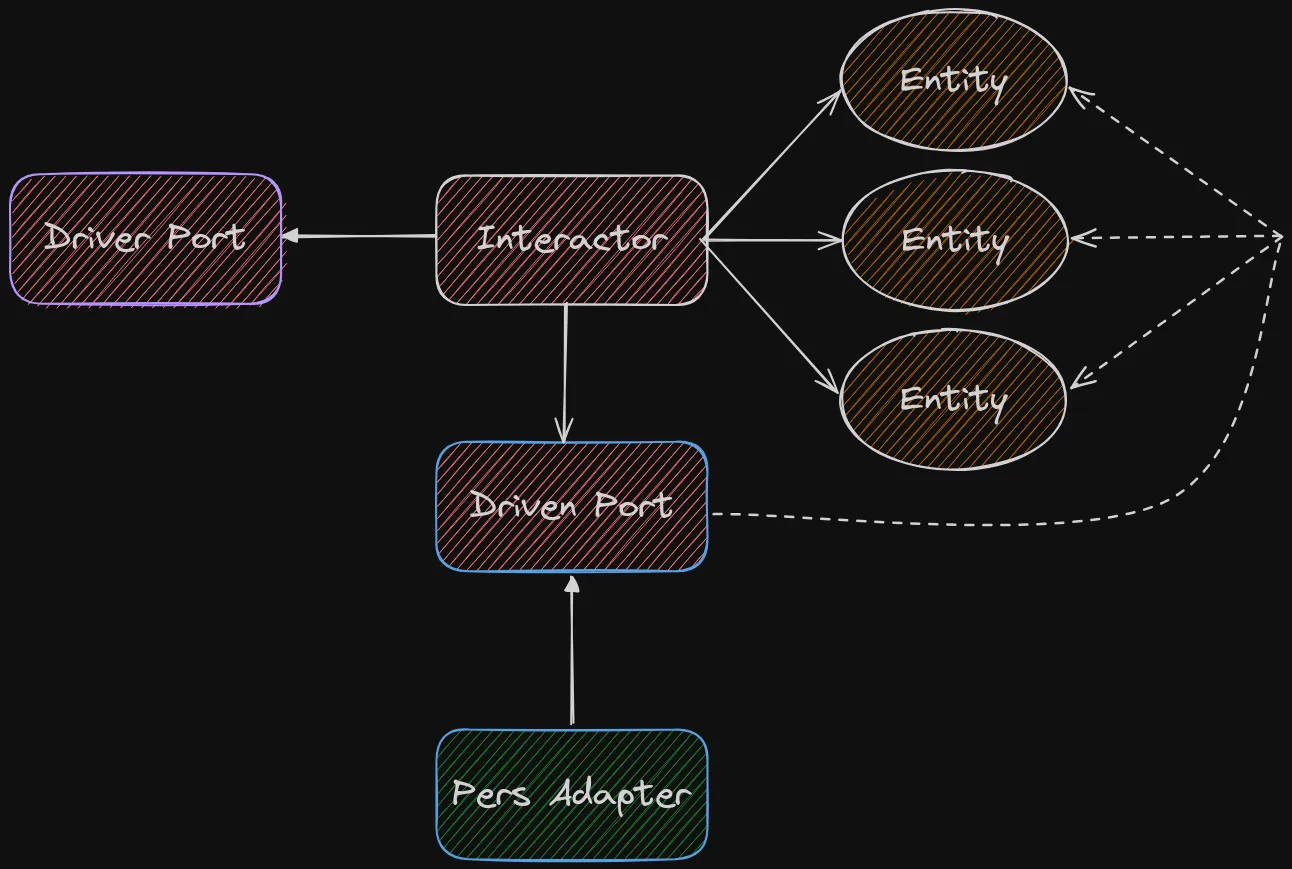
Think of the Interactor as the implementation of a use case of the application.
Thanks to Ports & Adapters, we know that a use case should be defined as an abstraction to ensure inwards dependency.
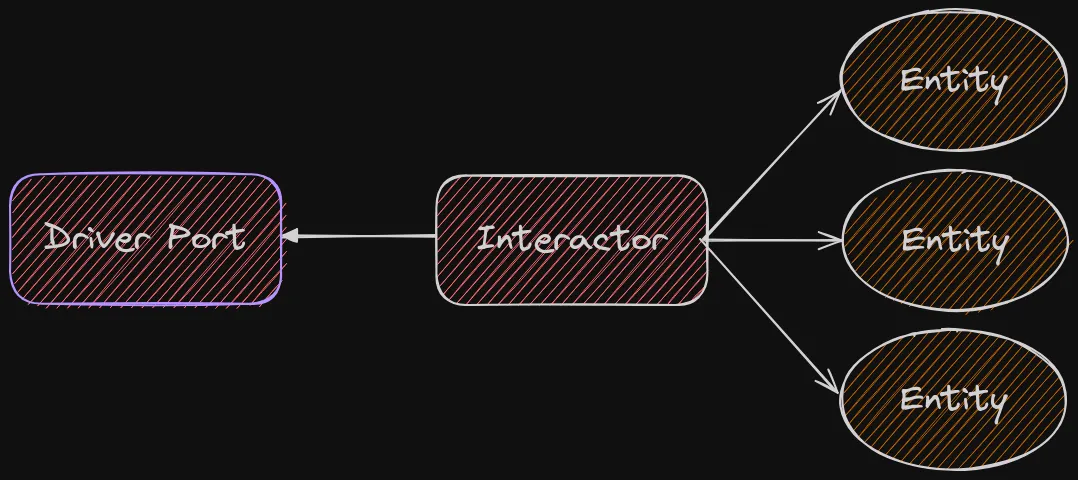
So if a use case is an abstract concept of ‘what needs to be done’, the Interactor is the concrete implementation of ‘how exactly it will happen’.
Entities usually require some sort of persistence, we can use a Driven Port/Adapter pair for that.
Let’s also represent the actor that will use the Driver Port from before, as well as the data structure (DTO) that will be shared between it and the Interactor.
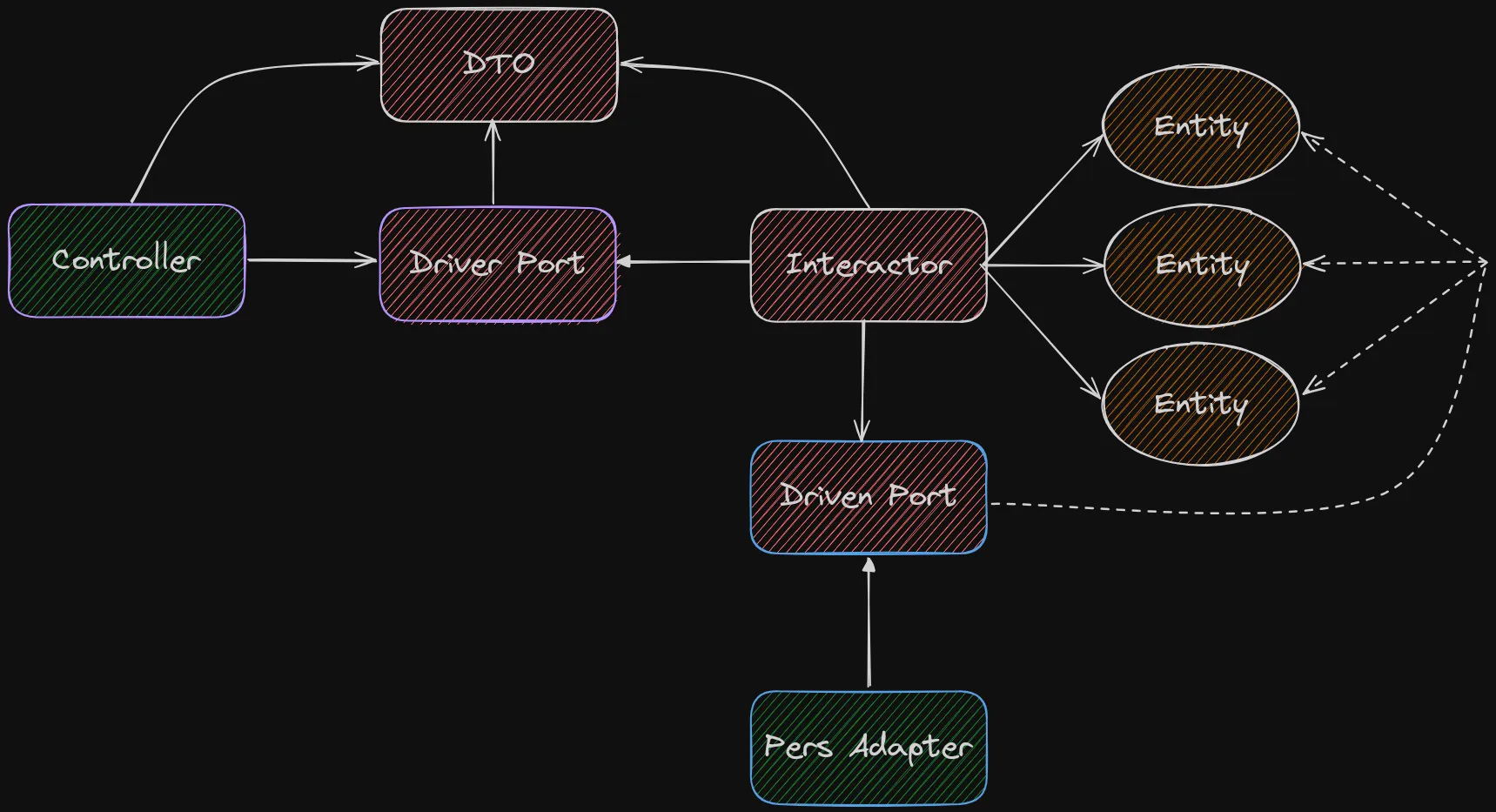
The controller could just as well be a CLI or a GUI.
Using a DTO here allows us to avoid exposing the Domain Entities outside the boundaries of the application. Speaking of boundaries.
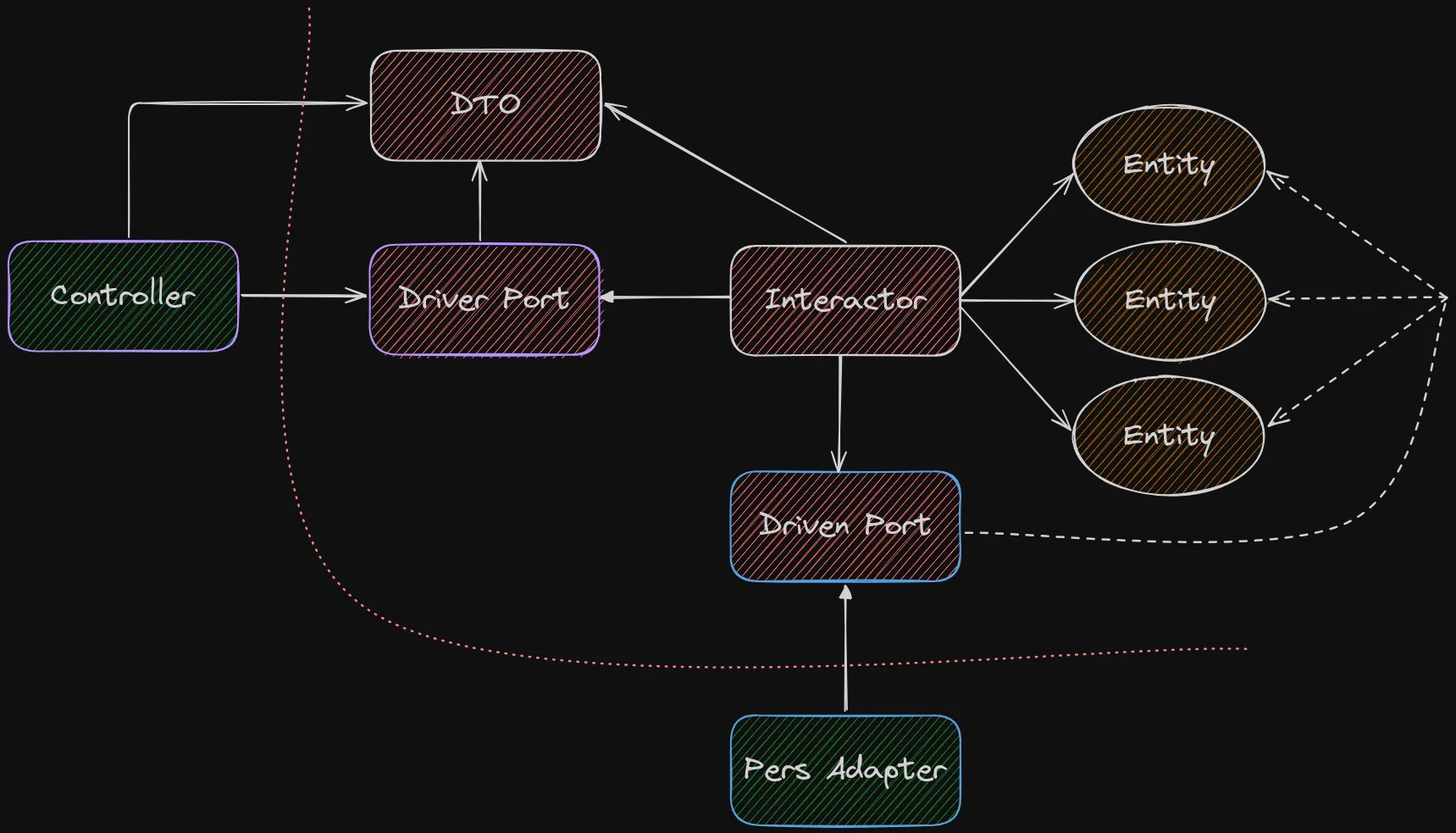
The red line marks the limit of our application logic and separates it from the pieces of the system that are necessarily coupled to the Infrastructure.
Now suppose that, when something happens in the system, we want to notify the user or update a UI element.
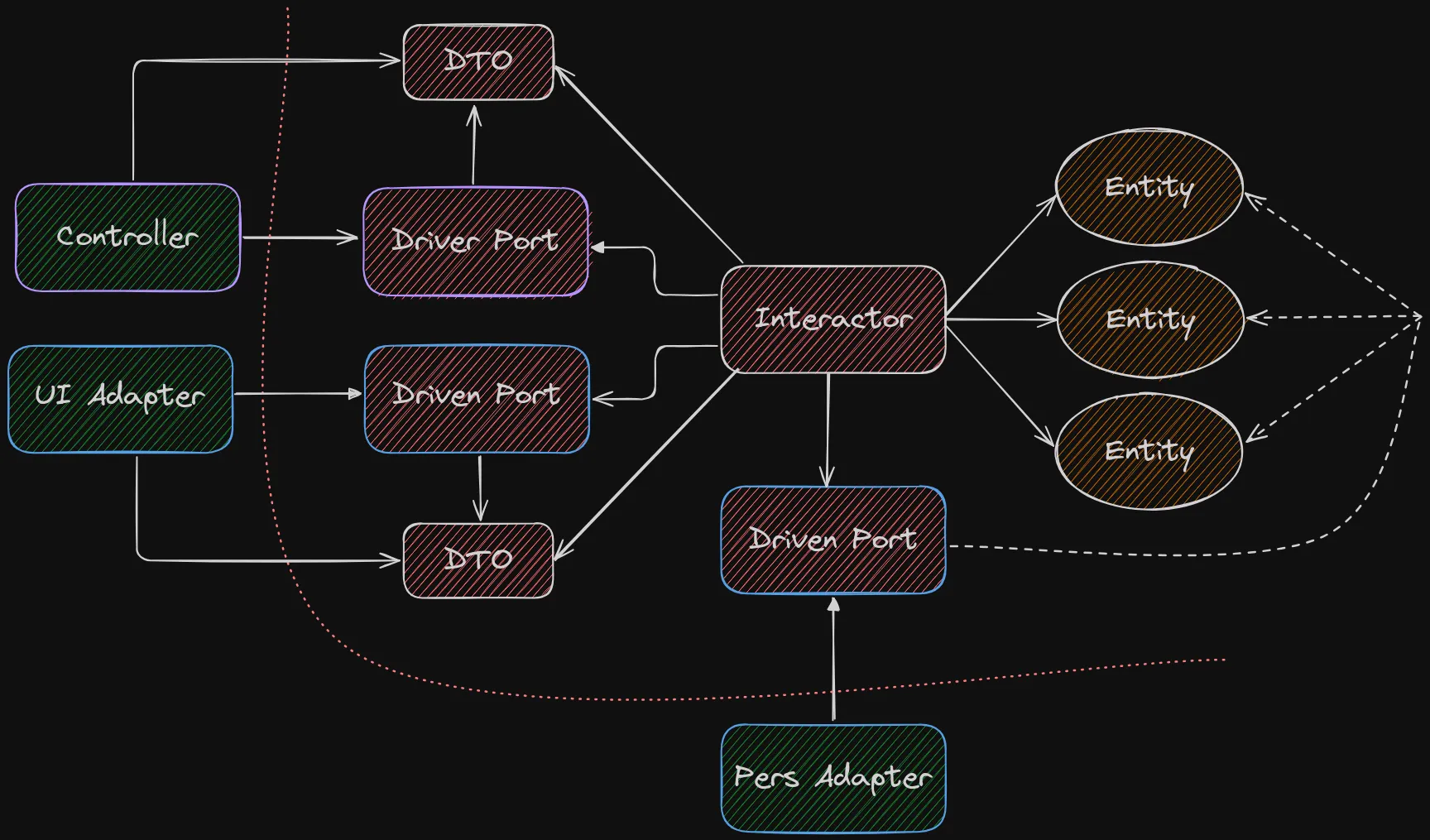
Or using Uncle Bob’s terminology:
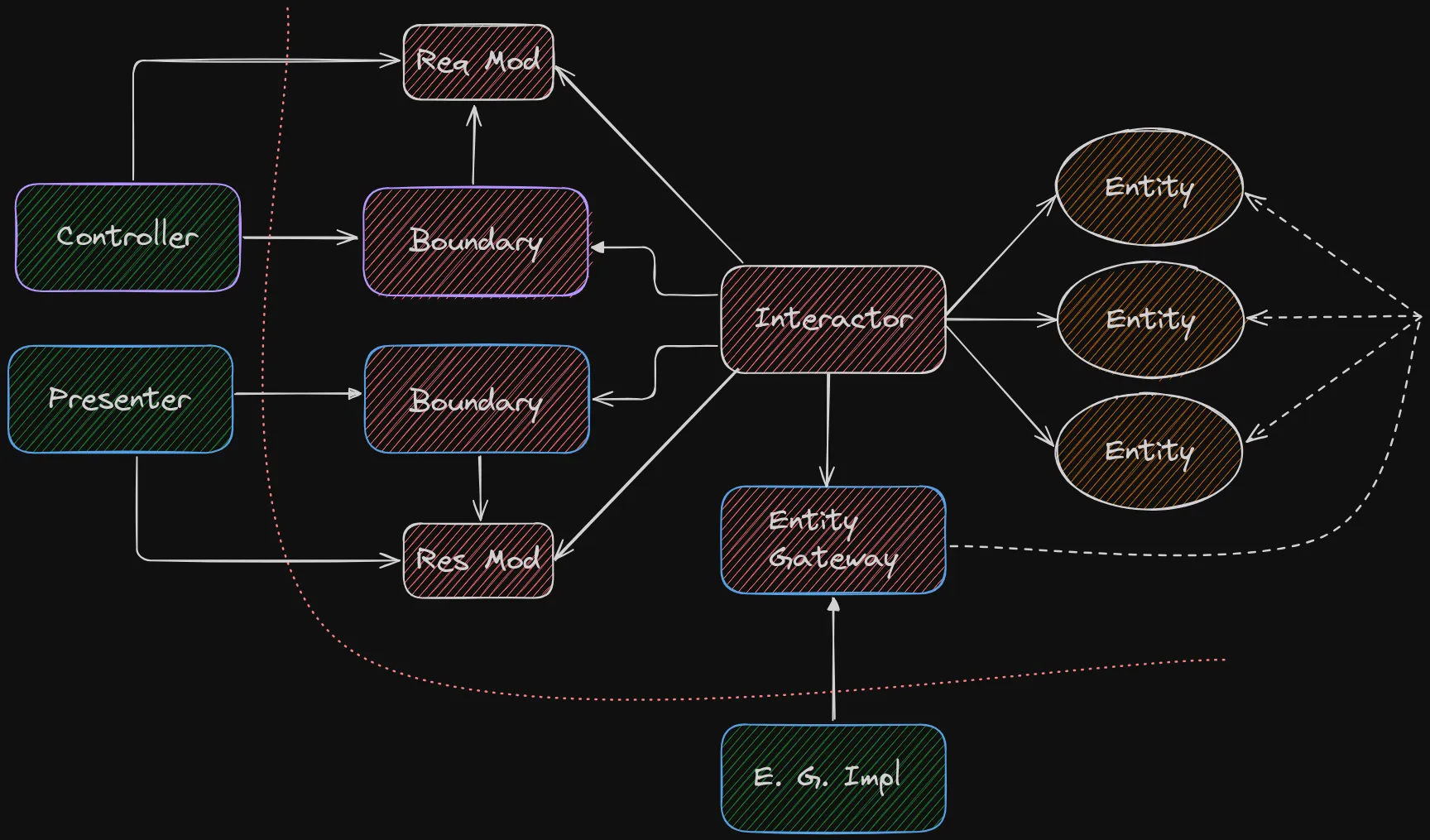
With this, we are back to his original diagram.
Let’s review how the flow of execution would go for an incoming HTTP request:
- The Request reaches the Controller
- The Controller:
- Dismantles the Request and creates a Request Model with the relevant data
- Through the Boundary, triggers the Interactor
- The Interactor:
- Finds the relevant Entities through the Entity Gateway
- Orchestrates interactions between entities
- Creates a Response Model with the relevant data and sends it to the Presenter through the Boundary
The diagram in the lower right corner of the first image on the original post might help visualize what’s going on.
{kind=link}
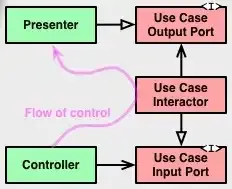
Swap ‘Use Case Output/Input Port’ for ‘Boundary’.
Footnotes
-
From the original article ↩
-
From the EBI architecture ↩